Running the Blueprint on a Shop That Doesn't Exist
I invented a small metal shop, gave it the messy spreadsheets a real one would have, and ran my own tool on it end to end. It found two hidden money leaks, and three things the tool was getting wrong.
I built a metal shop that does not exist, gave it the same messy spreadsheets a real one would have, and pointed my own tool at it. Within an afternoon it had found two ways the shop was quietly losing money, and three things my tool was getting wrong.
The tool is the Operations Blueprint: answer a few questions about a small manufacturer and it generates a foundation-first plan, and now a starter repo an AI coding agent can build from. It is the practical front end of the framework I document here, the same method behind the platform I built. But a plan you cannot watch run is just a claim. I wanted to run one all the way through, on a real shop’s worth of data, without touching a real shop. So I built a sandbox.
The shop
Northline Metalworks, invented. Seven people, built-to-order steel shelving and racking, plus a steady stream of one-off fabrication. It runs the way most small manufacturers actually run: QuickBooks for the books, and a stack of Excel for everything QuickBooks cannot do. That is not a strawman. Around 54% of plants still run on paper and spreadsheets, and roughly 83% of small manufacturers use Excel for core work. QuickBooks keeps the books but does not understand turning steel into a shelf, so the real operation lives in spreadsheets and gets re-entered by hand.
I generated six workbooks the way a real shop keeps them, mess and all: a materials price list the owner updates whenever an invoice comes in higher, a labor-rate calc set “sometime last year,” a quote template copied for every job, cut lists, a customer list, and a hand-logged production log. Inconsistent units, a blank-cost “misc” line that absorbs anything nobody wants to itemize, and one quote with a sell price typed straight over the formula.
What I did
I fed Northline’s ten answers into the blueprint. It produced a data model tailored to this shop and a starter repo. From that repo I built the smallest honest slice: one cost engine, quote pricing, a single report, and an ingestion step that reads the six spreadsheets into the database. Then I loaded the data and looked at what came out.
The whole thing turns on one idea I keep coming back to: pricing is a join. Material is the quote’s line items joined to the price list. Labor and overhead are its hours joined to the station rates. Everything prices through that one function. A quote for ten shelving units came out at $4,106.70, and it matched a hand-check to the cent.
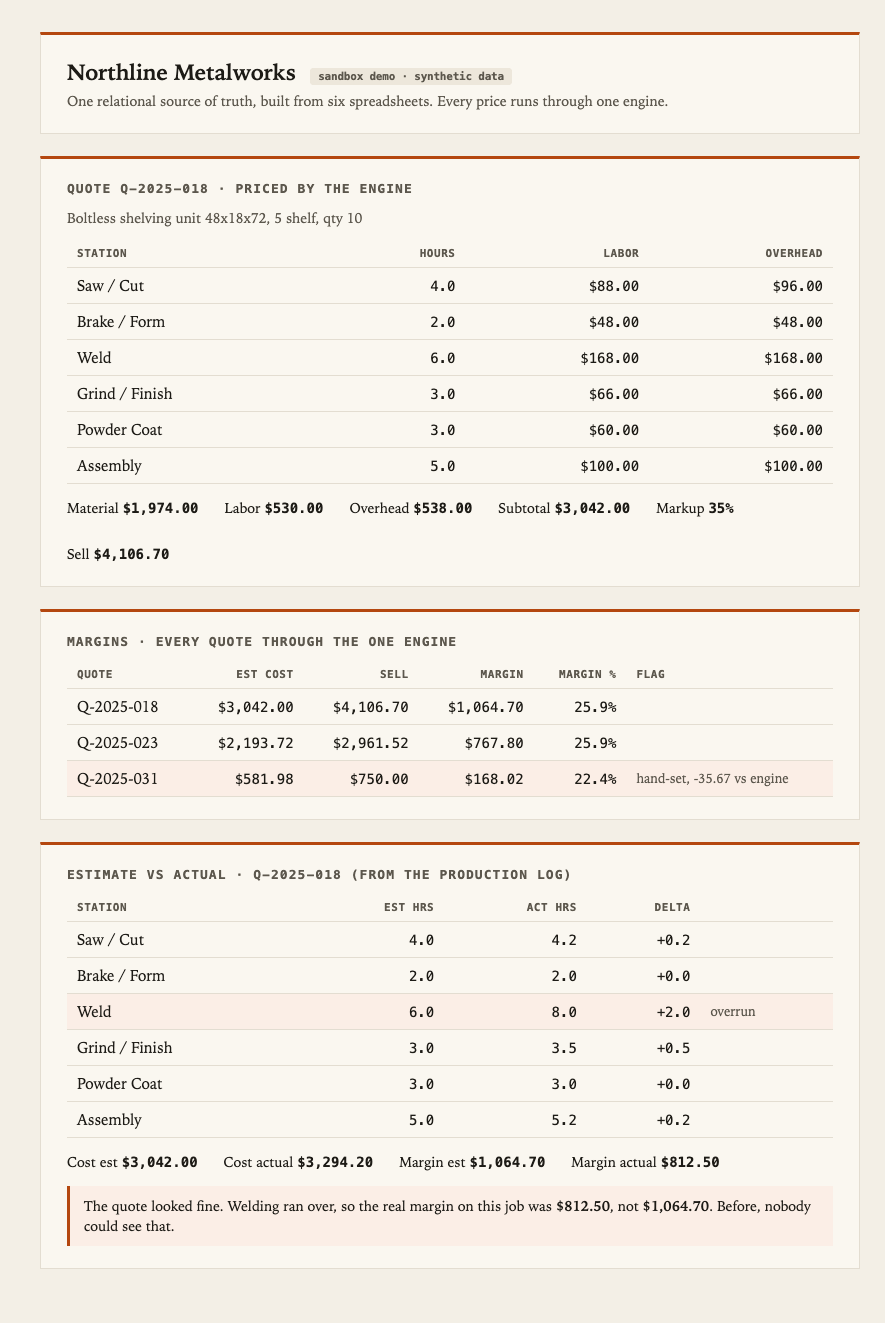
What it found
Priced through one engine, every quote is finally comparable. Two of Northline’s three sat at a healthy 26% margin. The third, a custom handrail, had a sell price of $750 typed in by hand. The engine said $785.67. In the spreadsheet that override was invisible, one number among thousands. Through one engine it is a flag, the moment it happens. Small money on its own, but it is the kind of leak that is everywhere and never counted.
The second one is the one that matters. A single job had its actual hours logged, so I could compare the estimate to what really happened. The estimate looked fine. But welding had run from six hours to eight, and once that flowed through, the real margin on the job was $812.50, not the $1,064.70 the quote implied. The owner would have said that job “felt tight” and could not have told you why. Now the number, and the exact station, are right there. That gap between estimate and actual is the most valuable thing a shop can measure, and almost nobody does, because in a spreadsheet estimate and actual never meet.
Here is the part worth sitting with: neither finding needed new data. The override and the overrun were both already in the shop’s own files. They just could not be joined or compared.
The tool was wrong three times
The demo was not really the point. What the run taught the tool was. Three gaps showed up that no amount of thinking at a desk had surfaced.
Northline quotes by building up materials and operations for each job, not by picking a finished product off a catalog. My export had quietly assumed a catalog. That is a real modeling mistake, and the shop’s data caught it in about ten minutes.
There was no step for importing the spreadsheets you already have, which is the very first thing a real shop needs and the exact place all the mess lives.
And the cost engine could double-count overhead if you were not careful, and could silently drop a line it was unable to price.
I fixed all three in the blueprint, confirmed the fixes only appear for the shops they apply to, and regenerated Northline’s plan so it now carries them. A shop that does not exist made the tool better for the ones that do. That is the feedback loop the whole method rests on, turned on itself.
What it means for you
If you run on spreadsheets, the uncomfortable and useful truth is that the data to catch your own leaks is probably already there. Northline did not have to measure anything new. It was all sitting in files that could not talk to each other. Structure the data once, price everything through one engine, and close the loop from actuals back onto estimates, and the operation becomes legible in a way it simply is not when the facts are scattered across tabs.
You do not need a big system to start. You need one honest slice: the thing that prices your work, and the comparison that tells you whether the price was right. That is what the shape of the system looks like from the ground floor.
Northline is made up, and every number in it is invented. But the shape of its problems is not, and neither is the fix. The next thing I want to do is run this again on a different kind of shop, and see what it teaches the tool the second time.
What the repo grew after this run
Since this ran, the engine’s repo has grown into a proper open-source package. It has a command-line tool that takes the same ten answers as the browser version, a test suite that checks the schema’s integrity across all 104,976 possible answer combinations, and a gallery of pre-generated blueprints for four more invented shops, so you can read full plans and schemas without answering anything. And the two procedures this run produced, the spreadsheet ingestion and the vertical-slice build order, now ship in the repo as agent skills at v0.1, labeled honestly: validated on one shop so far. I wrote a short note on why shipping those matters.
See it for yourself
Everything here is real and runnable, just on invented data:
- The report, live: the same view as above, as an actual page.
- The six sample spreadsheets: Northline’s messy “before,” to open in Excel.
- The starter repo the blueprint generated: the tailored plan and scaffold, the same kind the Operations Blueprint produces for your own answers.
- The engine itself: open source (MIT), the code that generated all of this.
Everything here, the shop, its people, its customers, and its numbers, is synthetic and built for demonstration. It is generic methodology run on invented data, not any real company’s system.